SocialSync
How Eric reduced SocialSync’s webhook database load by 80%
SocialSync processes millions of webhooks daily from social media platforms. Their primary database was buckling under the write load, and the engineering team had run out of ideas.
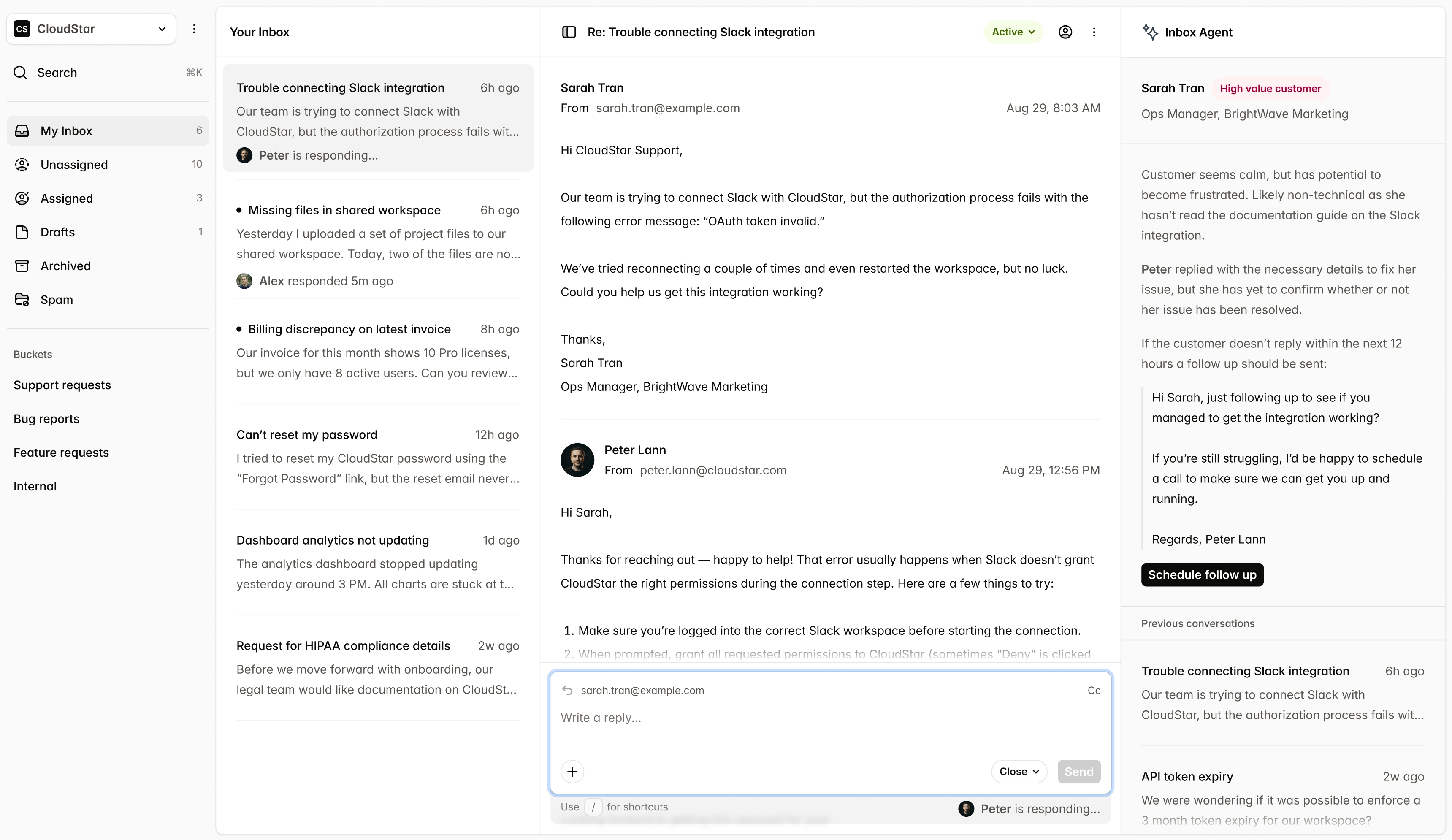
- 80%
- Less database load
- 180ms
- P99 processing time
- £800/mo
- Infrastructure saved
The challenge
SocialSync's webhook ingestion pipeline was writing every incoming event directly to their primary PostgreSQL database. At peak times, the database was hitting 90%+ CPU utilisation and queries were backing up across the application. The team had added read replicas, but the problem was write-heavy — replicas didn't help.
The engineering team had spent two sprints trying to optimise the pipeline themselves, but without production-grade instrumentation they were guessing at root causes. They needed someone who could diagnose the problem systematically.
The approach
Eric began by instrumenting the entire webhook processing pipeline with distributed tracing and detailed database query logging. Within the first week, three critical issues became visible:
- Redundant writes — the same webhook was being processed up to four times due to missing idempotency checks.
- Synchronous processing — webhook handlers were blocking the event loop, creating a cascading backlog.
- No batching — each event triggered an individual INSERT instead of batched writes.
Eric implemented a deduplication layer using Redis, moved processing to an asynchronous queue, and introduced batched database writes that grouped events into efficient bulk inserts.
The results
Within six weeks, SocialSync's database CPU utilisation dropped from 90% to under 20%. The P99 webhook processing time went from 2.3 seconds to 180 milliseconds. The team was able to decommission two read replicas that were no longer needed, saving £800 per month in infrastructure costs.
More importantly, the team now had full observability into their pipeline. Future performance regressions would be caught immediately, not months later.
Ready to see similar results?
Book a free 20-minute call to discuss your performance challenges. No obligation.